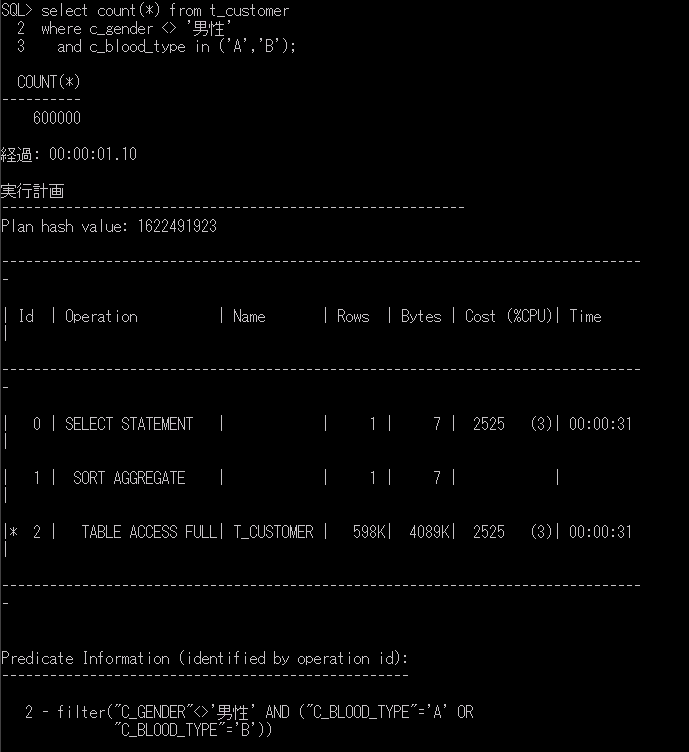
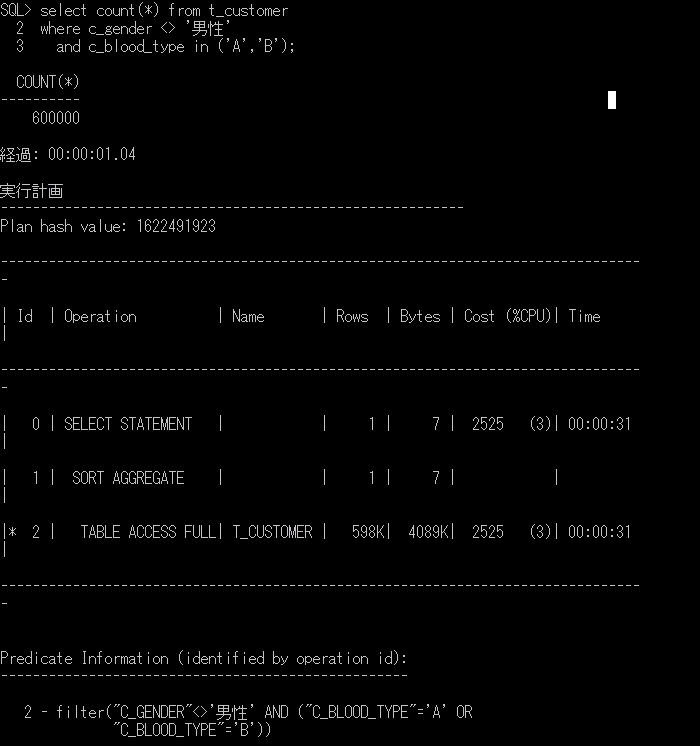
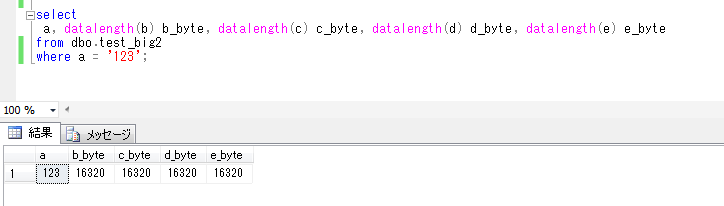
ITコーディネータのシュウです。

少し前に、山梨県の昇仙峡に妻と行って来ました。写真は、仙娥滝(せんがたき)と呼ばれる滝で、昇仙峡のシンボルである覚円峰(かくえんぼう)の麓にあり、駐車場から徒歩5分くらいのところにあります。この滝は日本の滝百選にも選ばれていて、落差は30mあり、地殻変動による断層によって生じたものとのことです。
学生時代に一度昇仙峡に行った記憶があり、岩の上から下を見て、高いなあと思った記憶があったのですが、今回は、渓谷に沿って紅葉を見ながら妻と歩くことにしました。
秋晴れの中、たくさんの観光客が遊歩道を歩き、渓流や紅葉を楽しんでいました。カップルが皆手をつないで歩いていたので、私も妻と手をつなぎながら、久しぶりに夫婦で自然を満喫することができました。
<本日の題材>
データベースメール(SQL Server)
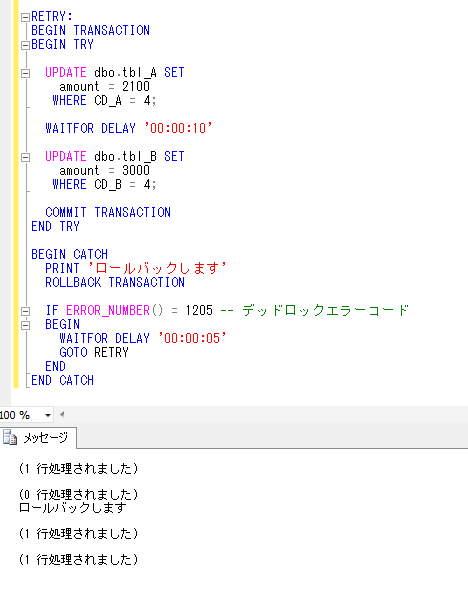
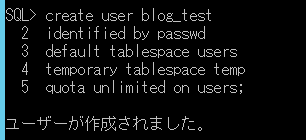
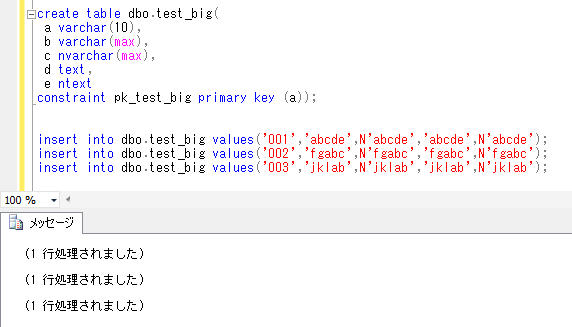
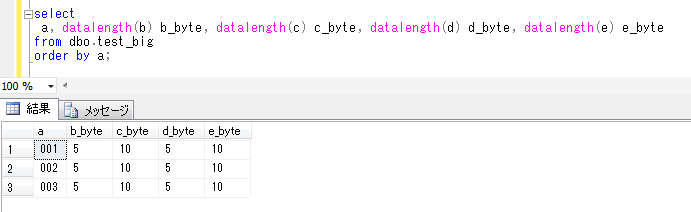
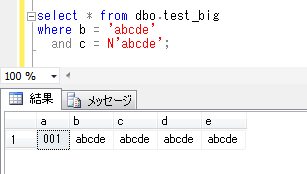
会社の同僚が、お客様のシステムで、SQL Serverのデータベースメールの機能を利用して、必要なタイミングでいろいろな情報をメールで知らせる仕組みを作ったということを聞き、今回はこれを題材にしてみます。ちなみに、確認したデータベースのバージョンは、SQL Server2014です。(データベースメールの機能は、SQL Server2012からのようです)
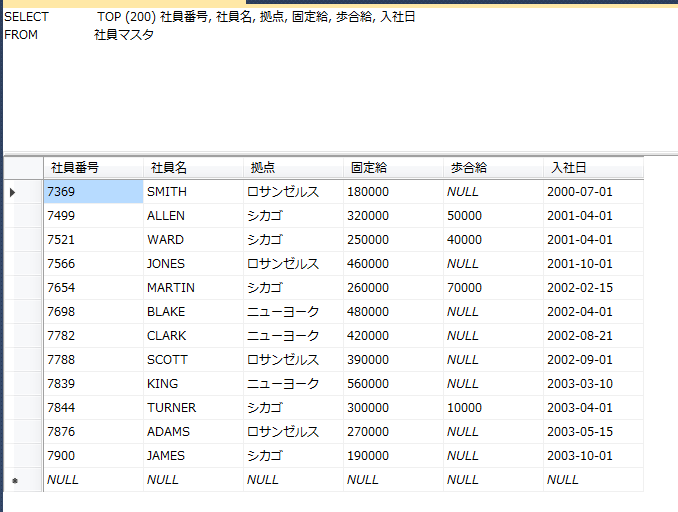
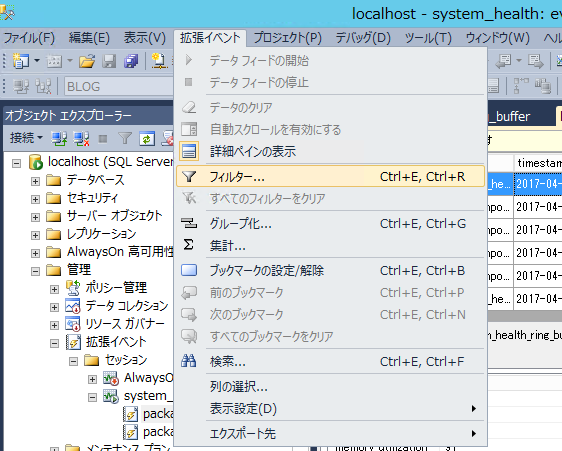
設定の方法ですが、SQL Server Management Studioを起動し、オブジェクトエクスプローラーの「管理」の中にある「データベースメール」を選択し、右クリックを押します。
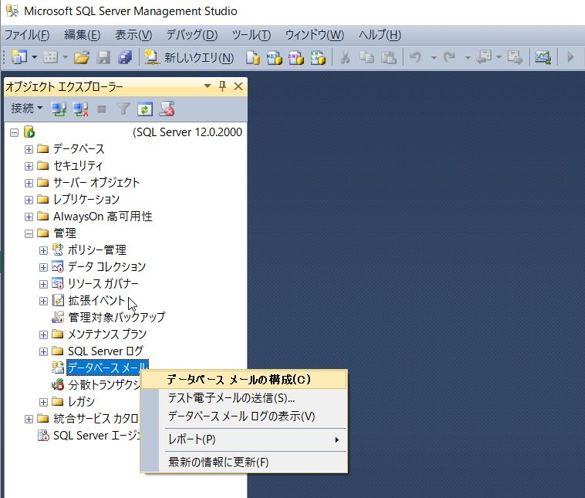
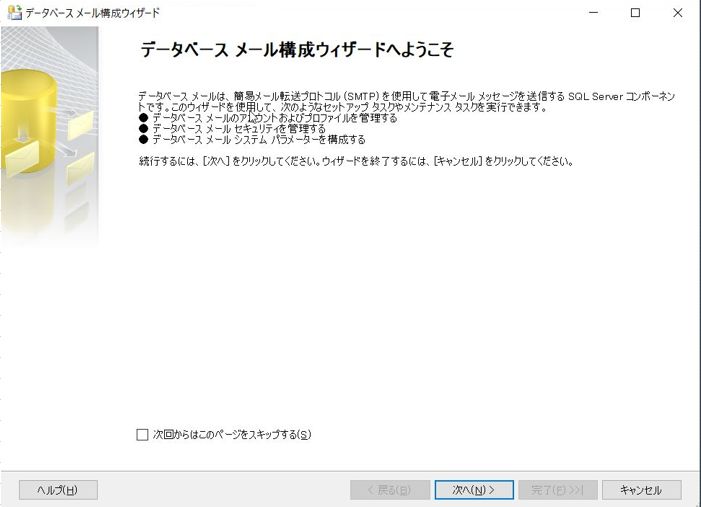
そこで表示されるメニューの「データベースメールの構成」をクリックすると、以下のようなデータベースメール構成ウィザードが表示されますので、「次へ」をクリックします。
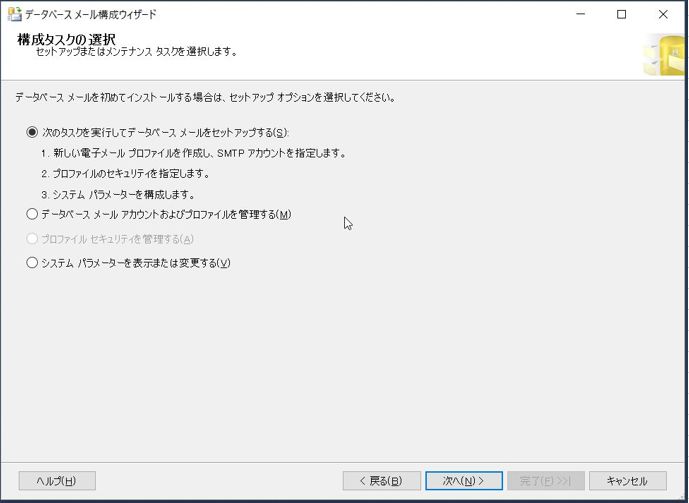
「構成タスクの選択」画面が出るので、「次のタスクを実行してデータベースメールをセットアップする」を選択した状態で、「次へ」ボタンを押下します。
すると、設定が初めての場合には、以下のようなメッセージが出ます。「データベースメール機能は使用できません。有効にしますか?」
ここで「はい」を選択します。

次に、「新しいプロファイル」設定画面が出てくるので、「プロファイル名」を設定した後、SMTPアカウントの「追加」ボタンをクリックします。
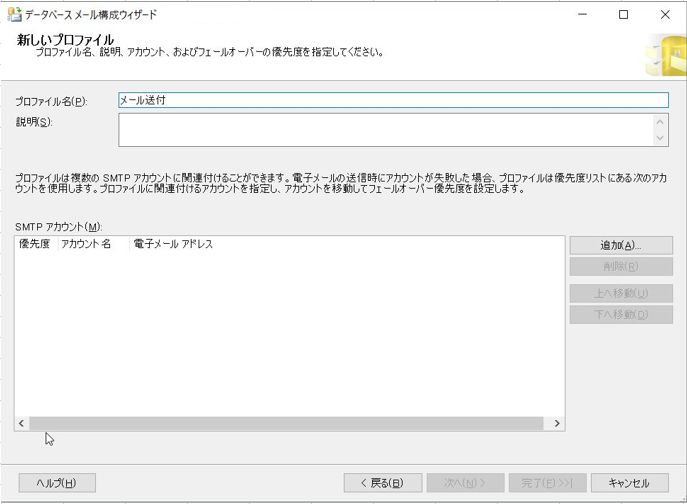
ここで、SMTPサーバーの設定を行います。
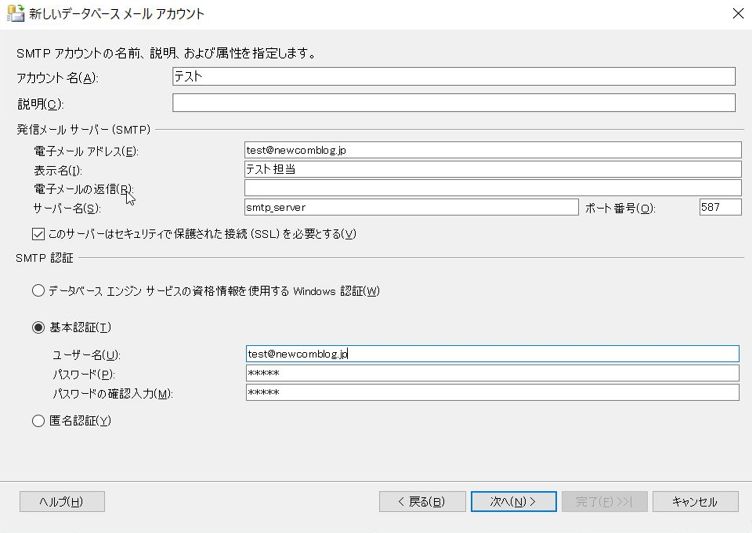
設定ができたら、「OK」ボタンを押下します。
(SMTP認証の設定が必要な場合は、その部分も設定します)
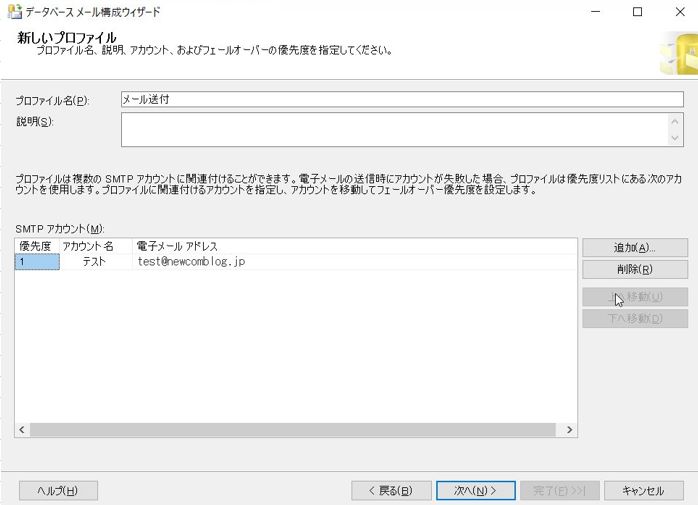
新しいプロファイルの画面に戻り、アカウントが追加されたているのを確認して、「次へ」ボタンをクリックします。
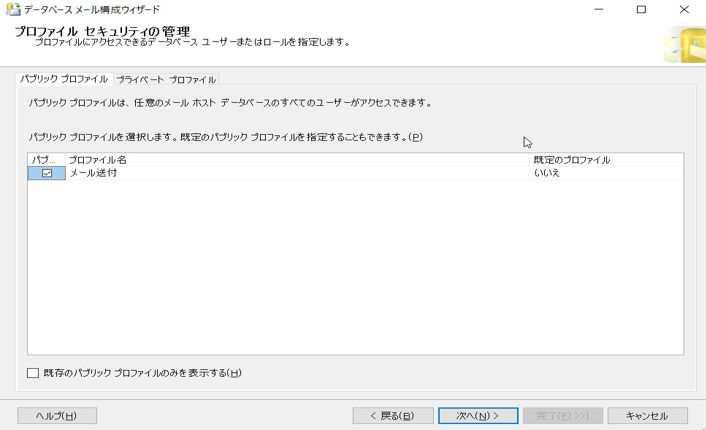
プロファイルセキュリティの管理の画面が出るので、確認してから「次へ」を押下します。
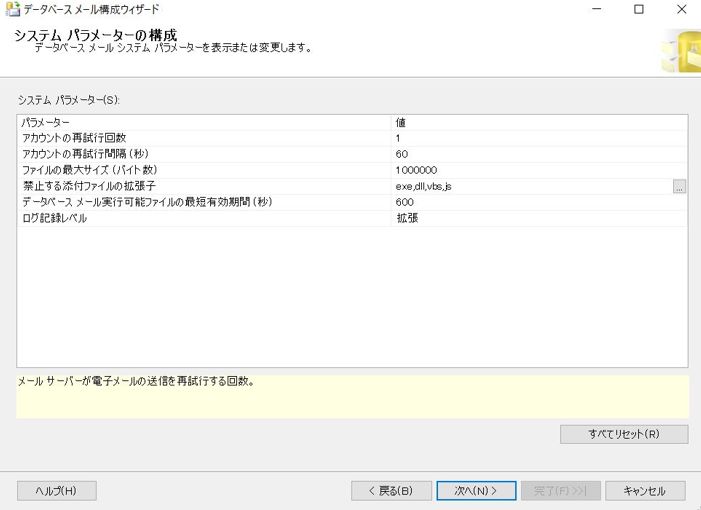
システムパラメータの構成の画面が出るので、こちらも確認して、「次へ」を押下します。このとき、禁止する添付ファイルの拡張子など、追加したい場合には、追加します。
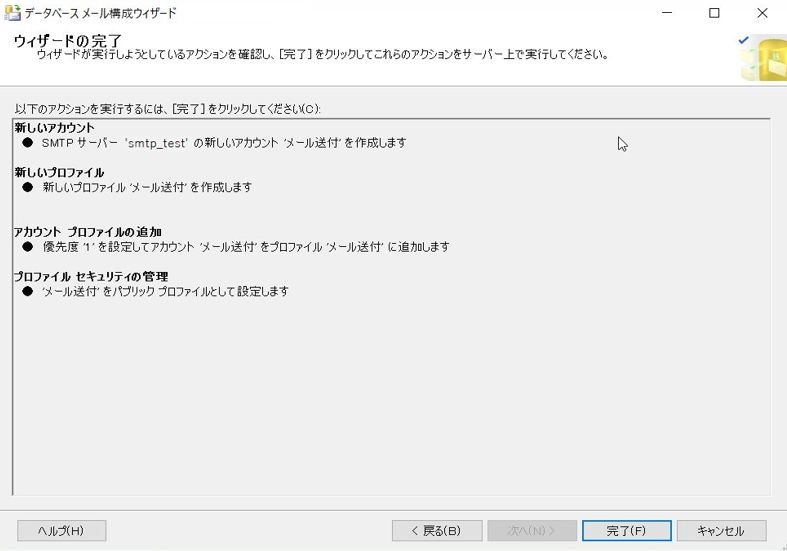
ウィザードの完了画面が出るので、「完了」を押下すると、構成を実行します。
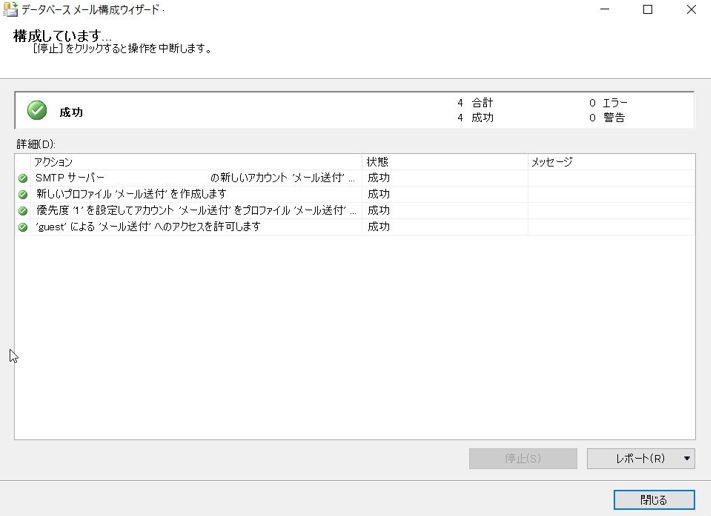
「成功」となれば、「閉じる」で終了します。
次に、メール送信のテストを行ってみます。
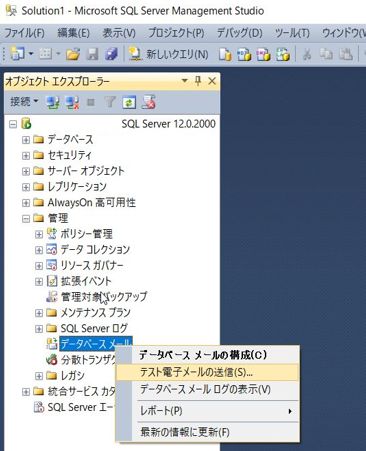
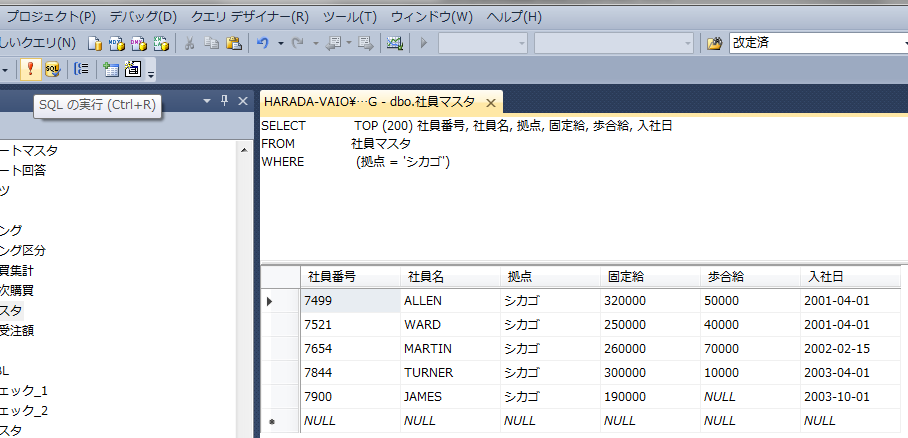
SQL Server Management Studioの「管理」の「データベースメール」を選択し、右クリックを押して、「テスト電子メールの送信」を押下します。
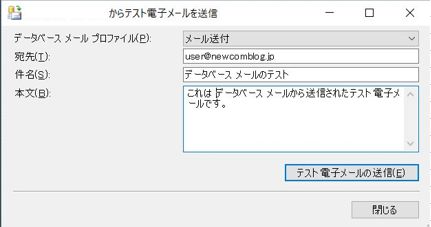
宛先を設定し、「テスト電子メールの送信」ボタンを押下します。
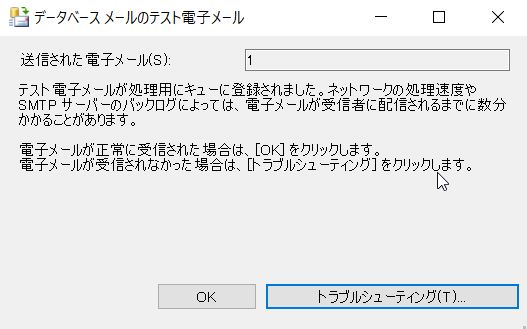
これによって、宛先のメールアドレスにメールが送付されることを確認します。
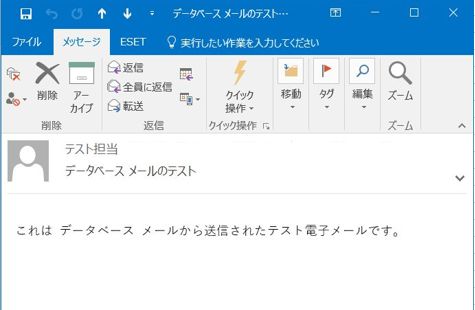
以上の手順で、SQL Serverのデータベースメールの設定とテストまで簡単にできました。
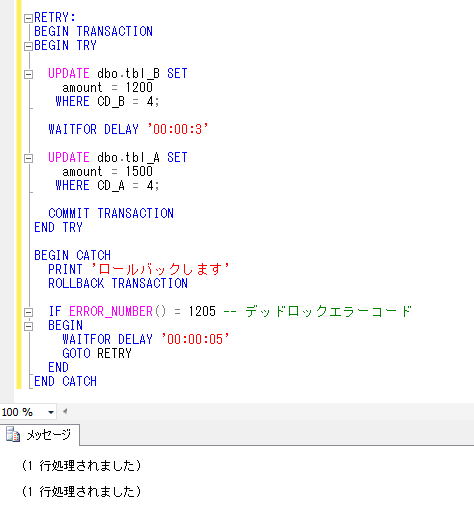
ただ、SQLを使用するアプリケーションの中で、このデータベースメールの仕組みを使ってSQLの結果などをメールで送付したいというのが目的だったので、SQLのプロシージャを使ってこのデータベースメールを送ってみます。
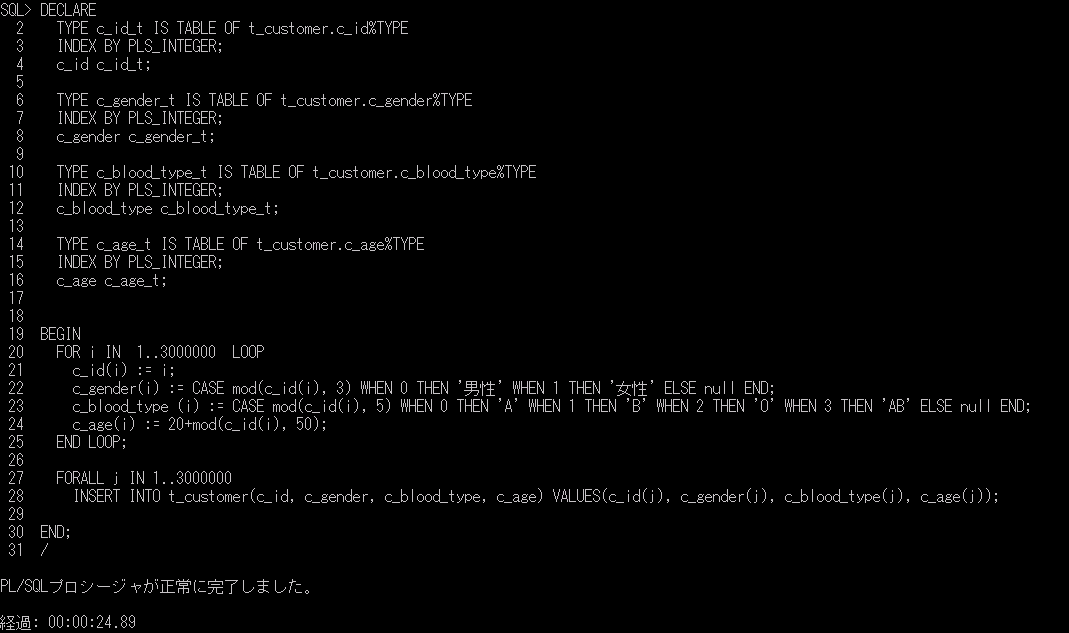
システムで用意しているプロシージャ「sp_send_dbmail」を使って、下記のようなSQL文を作成して実行してみます。
--メール送信
EXEC msdb.dbo.sp_send_dbmail
@profile_name = 'メール送付'
,@recipients = 'testuser@newcomblog.jp'
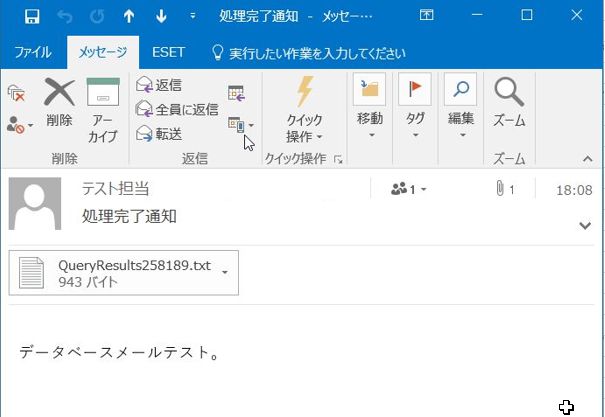
,@subject = '処理完了通知'
,@body = 'データベースメールテスト。'
,@query = 'SELECT * FROM BLOG.dbo.DEPT'
,@attach_query_result_as_file = 1
;
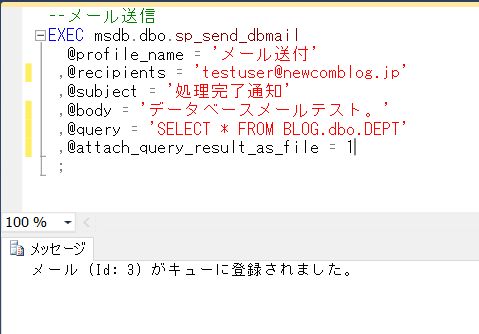
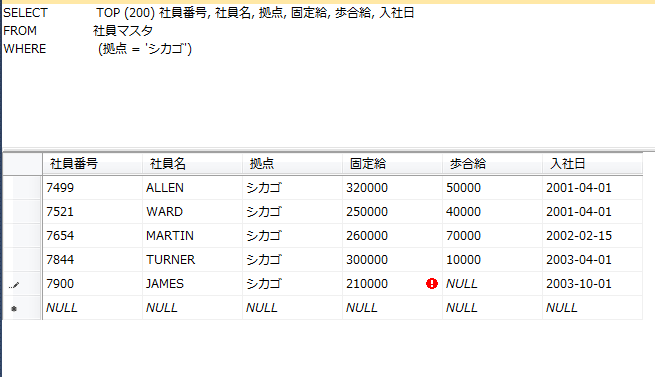
ここで、@querry 変数にSQL文を指定すると、メールにSQLの結果を付けることができます。(このとき、テーブルはデータベース名から指定します)
また、@attach_query_result_as_file = 1 と指定することで SQL の結果を添付ファイルにして送ることができます。
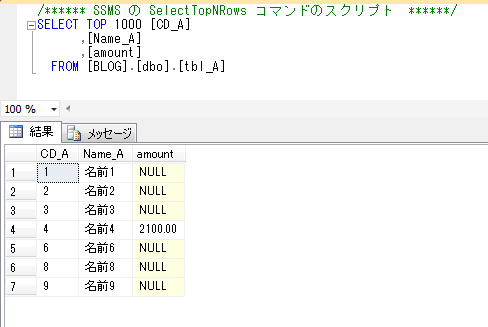
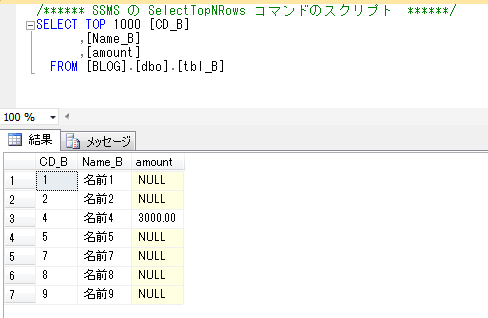
宛先のメールアドレスに上記の内容のメールが届けば成功です。
添付ファイルの中身を見ると以下のようになっています。
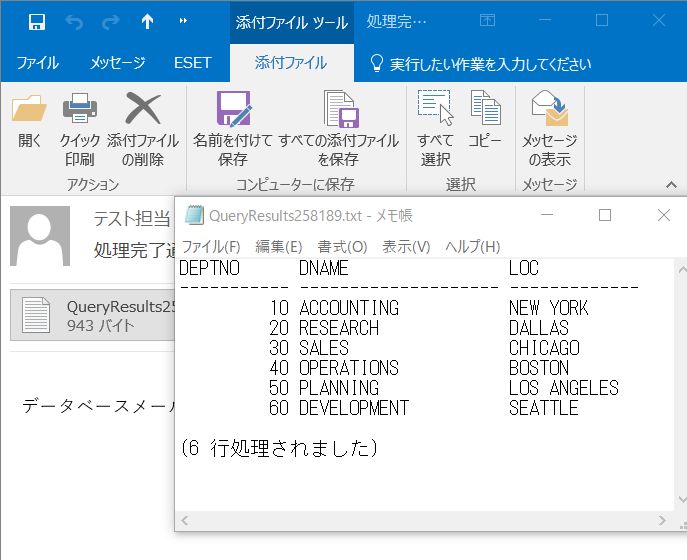
データベースメールの仕組みを使って、SQLの結果をメールで送付できることが確認できました。
今日は以上まで
にほんブログ村