ITコーディネータのシュウです。

上の写真は、11/4に日本三大花火大会の一つといわれる土浦の花火(正式名は土浦全国花火競技大会)に家族で見に行った時の写真になります。家族で車で行ったのは初めてで、ある程度余裕をもって家を出発したつもりでしたが、土浦市内に入ると、めちゃくちゃ車が混んでいて、止められるかなと思っていたモールのほうも、当日は駐車禁止ということになっていたり、通行止めがあったりして、全く車が進まない状況に。それでも何とか駐車場を見つけようと、市内をうろうろしていたところ、あるおじさんが声をかけてくれて、自宅の駐車場の空いているスペースを貸してくれるという奇跡のような出来事がありました。妻と娘も車に乗っていたこともあり、心配して声をかけてくださったのだと思いますが、本当に感謝でした。
<本日の題材>
OUTPUT句(SQL Server)
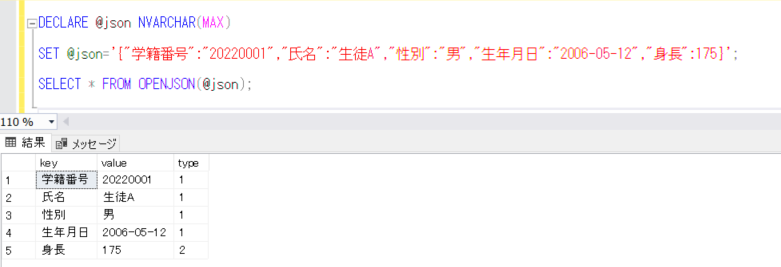
今回は、SQL Serverの機能で、OUTPUT句について取り上げてみたいと思います。これは、INSERT/UPDATE/DELETE/MERGEで追加/更新/削除 された行の情報を取得・出力できるというもので、とても便利な機能になります。最近の開発の案件の中で、この処理を使うことで、開発の要件を満たすことができました。
例)
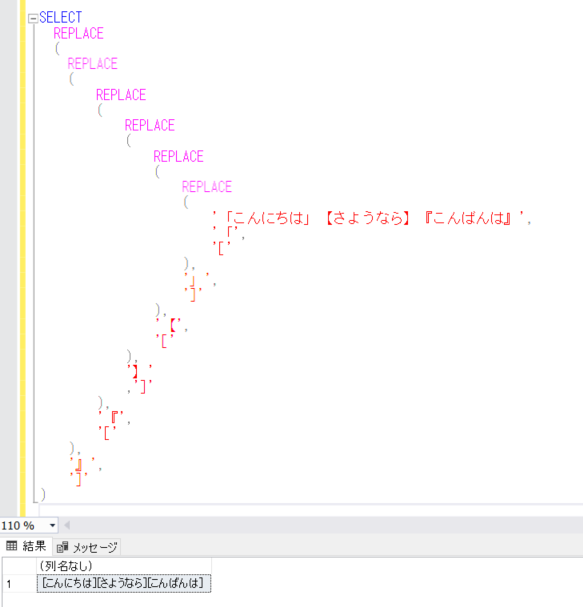
テーブルにデータを登録/更新/削除するときに、通常は登録/更新/削除したデータをその時点では確認できず、結果のデータと処理前のデータを比較することで確認できるというかたちになるかと思いますが、OUTPUT句を使うことで、その時点でそれらのデータを出力することができるので、それを確認したいと思います。
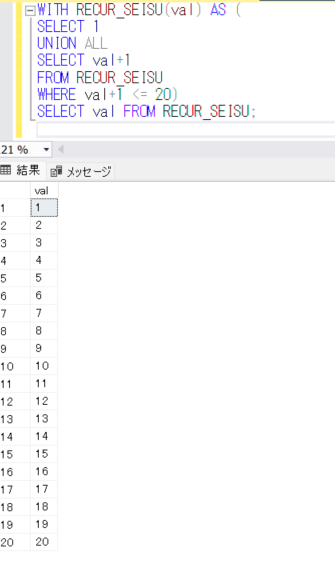
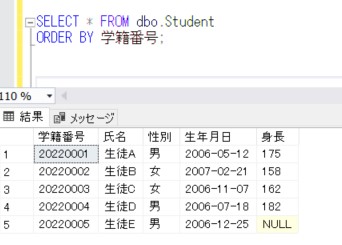
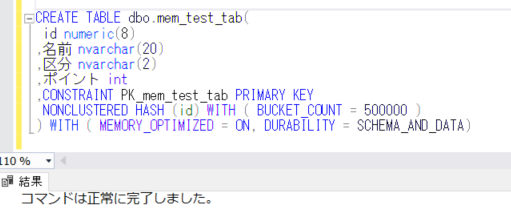
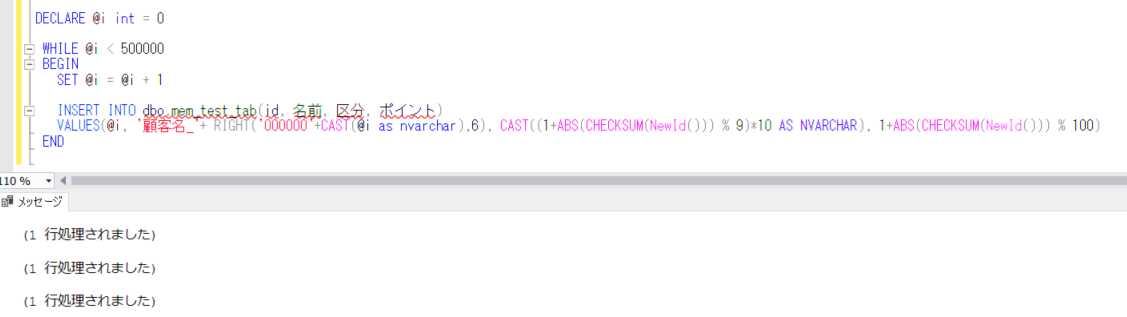
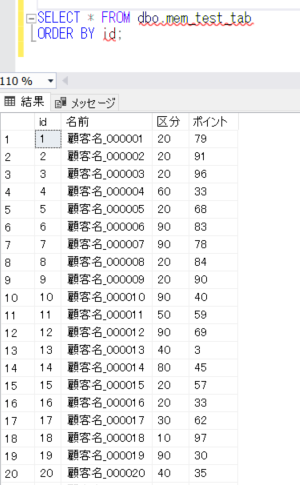
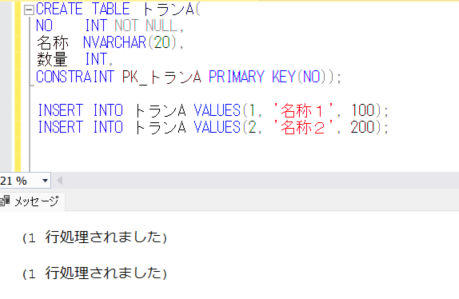
まず、今回確認するテーブルを作成し、初期のデータを登録します。
CREATE TABLE トランA(
NO INT NOT NULL,
名称 NVARCHAR(20),
数量 INT,
CONSTRAINT PK_トランA PRIMARY KEY(NO));
INSERT INTO トランA VALUES(1, '名称1', 100);
INSERT INTO トランA VALUES(2, '名称2', 200);
それでは、INSERT/UPDATE/DELETE の処理を実行するとともに、OUTPUT句によって出力してみます。
まず、INSERT から
INSERT INTO トランA OUTPUT inserted.*
VALUES(3, '名称3', 300);
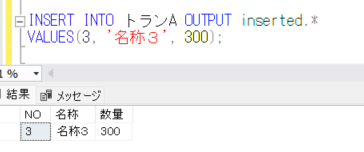
通常、INSERT文を実行すると、
(1 行処理されました)
というようなメッセージのみが出力されますが、OUTPUT句を使用することで、INSERTしたデータを出力することができます。
次に、UPDATEを試します。
UPDATE トランA SET
数量 = 400
OUTPUT deleted.*, inserted.*
WHERE NO = 3;
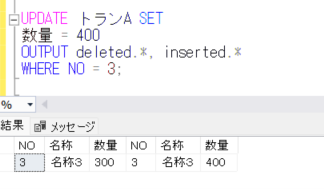
上記結果のように、deleted.* で更新前の(削除される)データ、inserted.* で更新後の(追加される)データを出力しています。
次に、DELETEを試してみます。
DELETE FROM トランA
OUTPUT deleted.*
WHERE NO = 3;
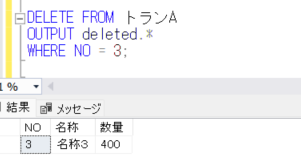
上記のように、DELETEされるデータを出力しているのが確認できます。
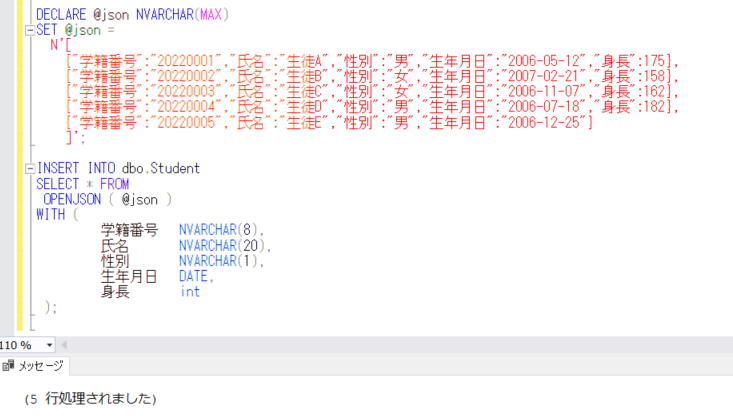
次に、MERGE処理でOUTPUT句を使用するために、トランAと同様の定義を持つワークテーブルを作成し、そこにもデータを登録します。
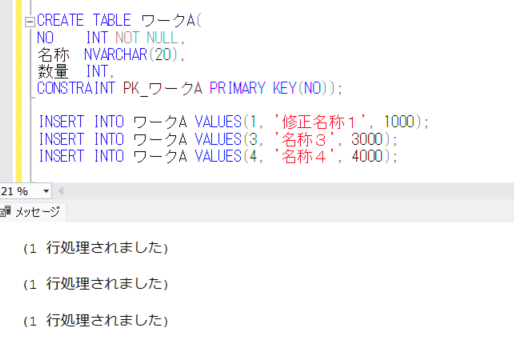
CREATE TABLE ワークA(
NO INT NOT NULL,
名称 NVARCHAR(20),
数量 INT,
CONSTRAINT PK_ワークA PRIMARY KEY(NO));
INSERT INTO ワークA VALUES(1 '修正名称1', 1000);
INSERT INTO ワークA VALUES(3 '名称3', 3000);
INSERT INTO ワークA VALUES(4 '名称4', 4000);
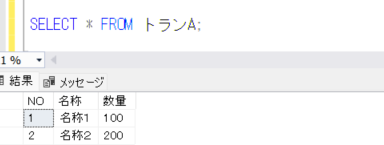
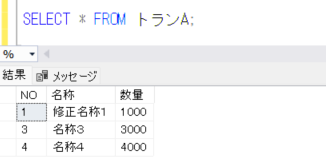
それでは、MERGEを実行する前に、再度トランAテーブルのデータを確認します。
トランAのテーブルに対して、ワークAのデータを参照して、キーがマッチするものは更新し、マッチしないもので、トランにはなくワークに存在するものは登録し、トランにはあるがワークには存在しないものは削除するMERGE処理を実行してみますが、このときに、OUTPUT句によって、更新・登録・削除のデータを出力してみたいと思います。
MERGE INTO トランA
USING ワークA
ON (トランA.NO = ワークA.NO)
WHEN MATCHED THEN
UPDATE SET
名称 = ワークA.名称
,数量 = ワークA.数量
WHEN NOT MATCHED THEN
INSERT (NO, 名称, 数量)
VALUES(ワークA.NO, ワークA.名称, ワークA.数量)
WHEN NOT MATCHED BY SOURCE
DELETE
OUTPUT inserted.*, deleted.*, $action;
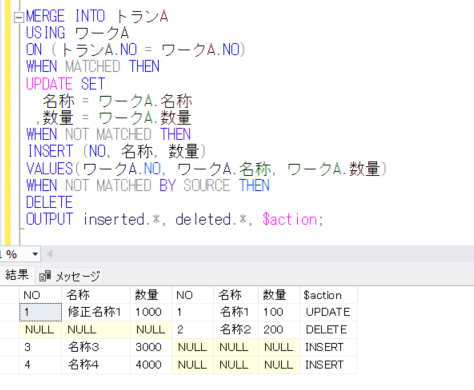
$action という項目に、UPDATE/INSERT/DELETE のどの処理が行われたのかが出力されます。
したがって、このOUTPUTの結果を一時テーブルなどに登録すれば、MERGE文などの処理の後に、登録・削除・更新されたデータをその後の処理で活用することが可能になります。
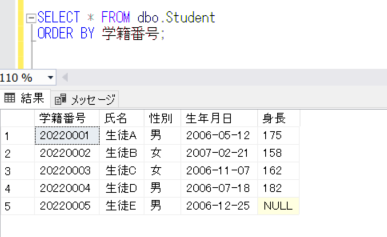
最終的なトランAの結果を確認してみます。
にほんブログ村