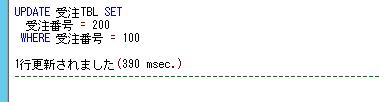ITコーディネータのシュウです。

今回も、ITC関連のネタです。ITコーディネータ協会では、毎年この時期にITCカンファレンスというものを開催しており、今年が14回目です。今年は10月30日(金)~31日(土)で行われます。
今年の大会テーマは「IoT新時代におけるITコーディネータのエボリューション~クラウド・Industrie4.0の可能性~」。ドイツが取り組んでいるIndustrie4.0(第4次産業革命)というものを取り上げつつ、日本版Industrie 4.0と言われる「つながる工場」の動きやITコーディネータ協会としての取り組みを紹介するということです。
HPは以下:
http://www.itc.or.jp/activity/seminar/itc_conf2015/index.html
近年、スマートフォンに代表されるようなコンピュータを内蔵した機器がインターネットに接続され、さらには様々なモノにセンサーなどを取り付け通信ができ、それらがつながる世界というような内容でIOT(Internet of Things)「モノのインターネット」という言葉をよく耳にするようになりました。スマートハウスやスマート家電などのスマート~という名前もよく使われますね。「つながる工場」、今、ものづくりの世界で大きな変革のときを迎えつつあるようです。それらを駆使することで、大きな飛躍のチャンスの可能性があるかも知れません。
<本日の題材>
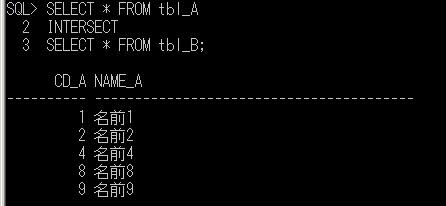
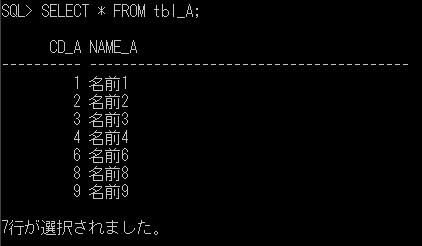
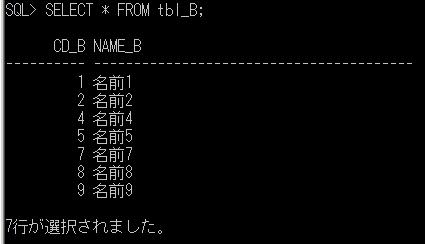
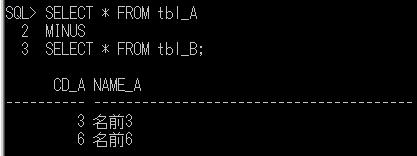
一時テーブル(2)
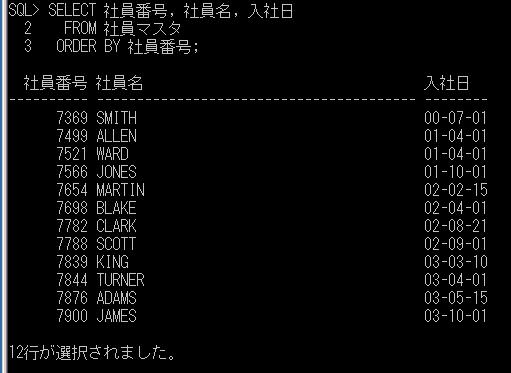
前回、一時テーブルの例としてOracleの場合を取り上げましたので、今回はSQL Serverについて例を上げて確認してみたいと思います。
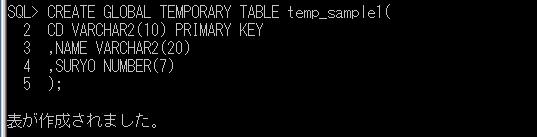
SQL Serverの場合のローカル一時テーブル作成の構文:
CREATE TABLE #表名(
列名 データ型
, 列名 データ型
, …
);
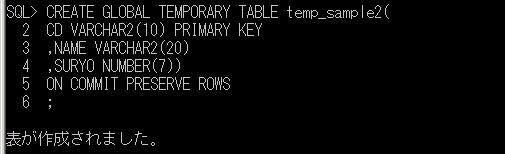
SQL Serverの場合のグローバル一時テーブル作成の構文:
CREATE TABLE ##表名(
列名 データ型
, 列名 データ型
, …
);
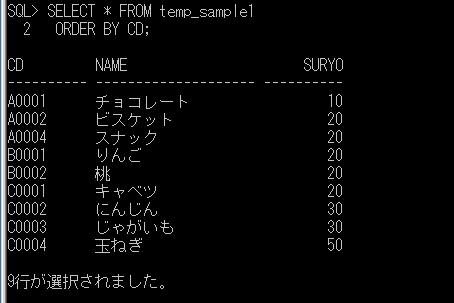
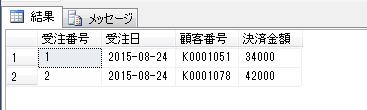
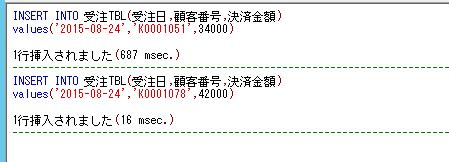
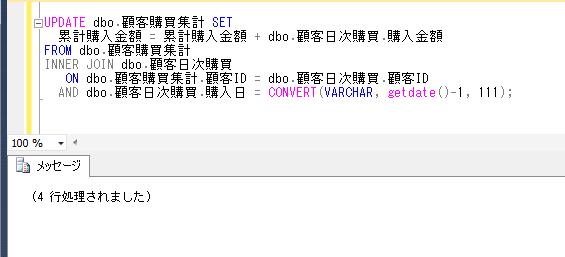
一時テーブルの使用例として、売上テーブルから顧客の初回購入日や購買回数などの購買履歴の情報を抽出して表示するような単純な処理を、ストアド・プロシージャで実行する簡単な例を作成してみます。
CREATE PROCEDURE dbo.顧客購買履歴情報抽出
@顧客ID VARCHAR(8)
AS
BEGIN
-- 一時テーブルの作成
CREATE TABLE #顧客初回購入(
顧客ID VARCHAR(8),
初回購入日 DATETIME
);
CREATE TABLE #顧客購入履歴(
顧客ID VARCHAR(8),
累計購入回数 decimal(7),
累計購入金額 decimal(9)
);
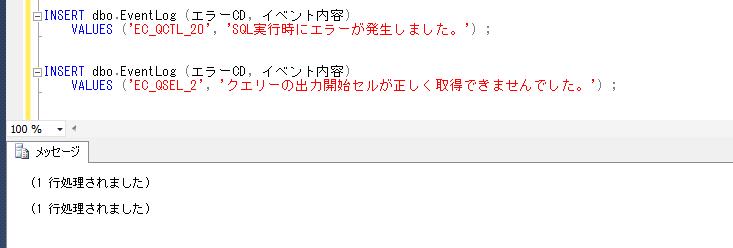
-- 初回購入日の抽出結果を一時テーブルに登録
INSERT INTO #顧客初回購入
SELECT 顧客ID, MIN(出荷日)
FROM dbo.売上
WHERE 顧客ID = @顧客ID
GROUP BY 顧客ID;
-- 累計購入情報の抽出結果を一時テーブルに登録
INSERT INTO #顧客購入履歴
SELECT 顧客ID, COUNT(*), SUM(売上金額)
FROM dbo.売上
WHERE 顧客ID = @顧客ID
GROUP BY 顧客ID;
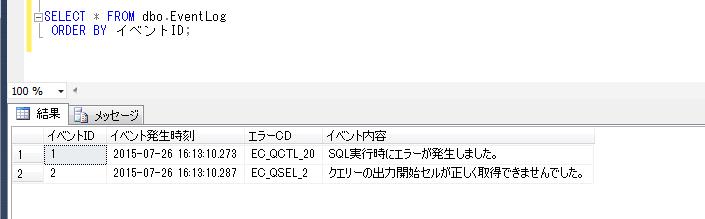
-- 顧客購買履歴情報の表示
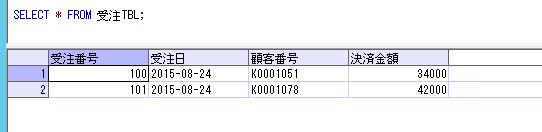
SELECT
A.顧客ID
, FORMAT(A.初回購入日,'yyyyMMdd') AS 初回購入日
, B.累計購入回数
, B.累計購入金額
FROM #顧客初回購入 A
JOIN #顧客購入履歴 B ON A.顧客ID = B.顧客ID;
END;
GO
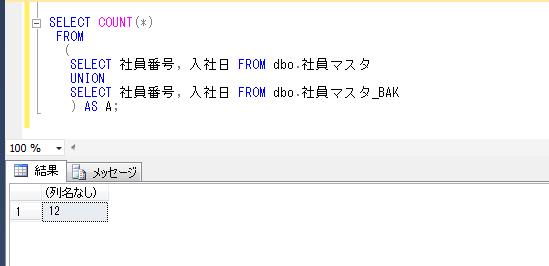
Oracleとは違って、プロシージャの中で一時テーブルを作成し、それらをジョインして抽出結果を表示するサンプルになります。
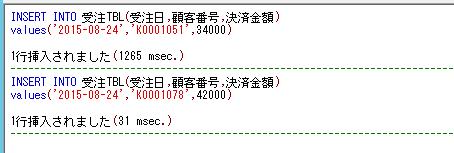
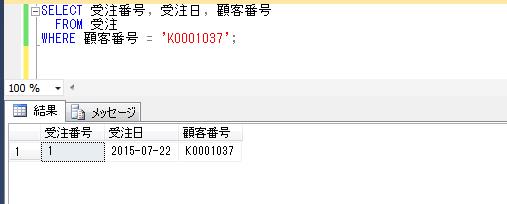
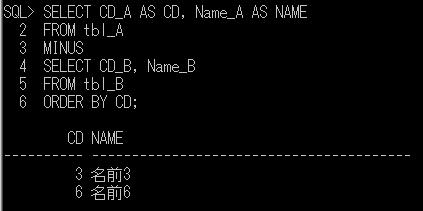
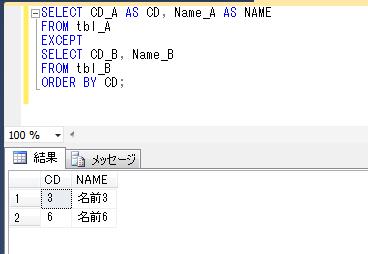
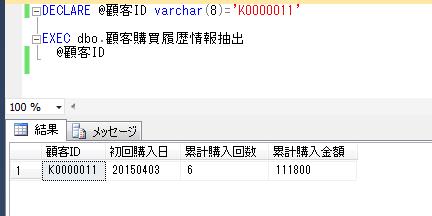
上記のプロシージャに顧客IDのパラメータを渡して実行してみます。
DECLARE @顧客ID varchar(8)='K0000011'
EXEC dbo.顧客購買履歴情報抽出
@顧客ID
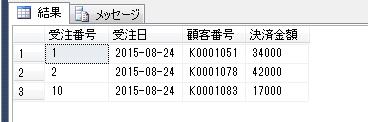
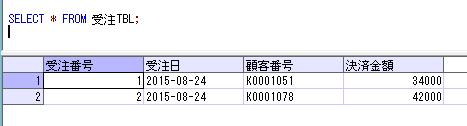
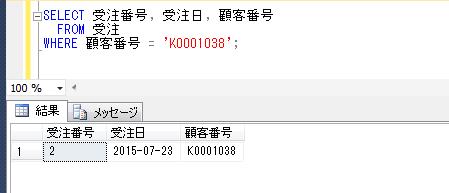
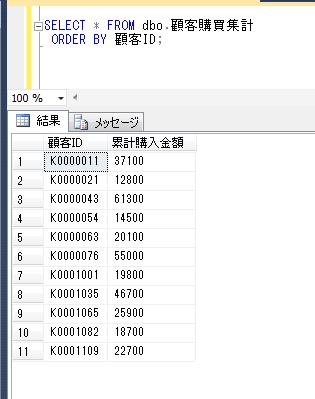
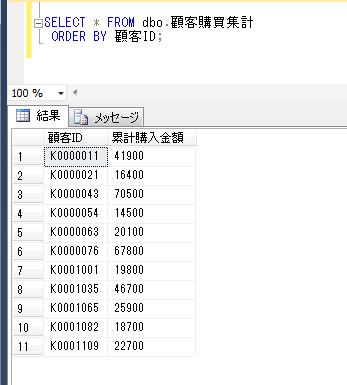
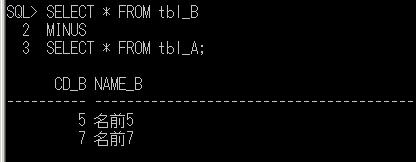
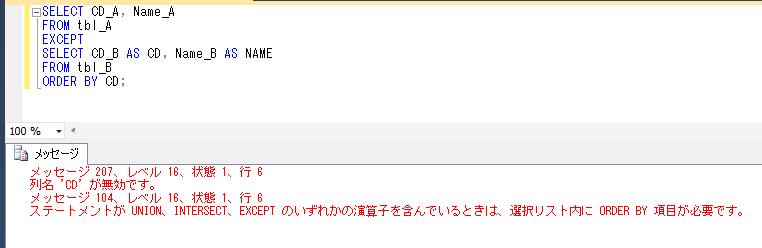
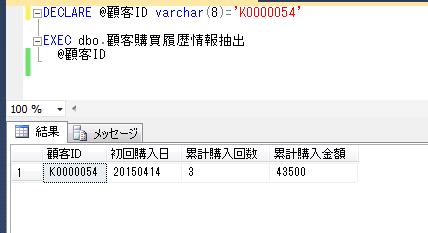
別の顧客IDをパラメータで渡して、再度実行結果を確認すると、
DECLARE @顧客ID varchar(8)=' K0000054'
EXEC dbo.顧客購買履歴情報抽出
@顧客ID
さて、SQLServerの場合のグローバル一時テーブルについては、あまり使ってみたことがないですが、どういうときに使うかを調べてみたところ、排他処理で使うケースがあるようです。
悲観的排他制御を行いたいときに、アプリケーションでコントロールする場合には、最初に排他用のフラグを立てて、そのフラグが立っている場合は、他のユーザは更新などの処理が実施できないというようなことを行うことがあると思います。
ただ、このフラグの制御を実テーブルで行うと、予期せぬかたちで処理が強制的に終了してしまった場合に、フラグが立ったままになってしまい、排他の状態が続いてしまって更新ができなくなってしまうなどというケースが出てきてしまうため、何らかのかたちで解除する方法を検討しなければなりません。
このときに、このフラグの制御を実テーブルではなく、グローバル一時テーブルを作成するというかたちで行うと、強制的に終了した場合でも、グローバルテーブルが自動的に削除されることで排他状態ではないと容易に判断できるということになるということです。
簡単に試してみたいと思います。
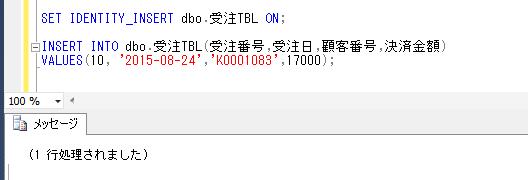
★排他をかけたいとき
CREATE TABLE ##排他チェック(
USERID VARCHAR(20),
処理時刻 DATETIME
);
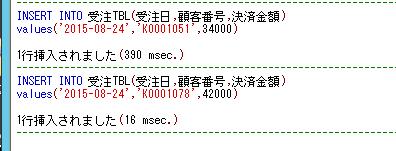
INSERT INTO ##排他チェック
SELECT '00001', GETDATE();
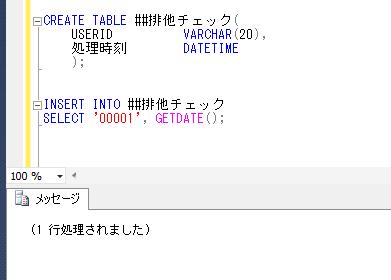
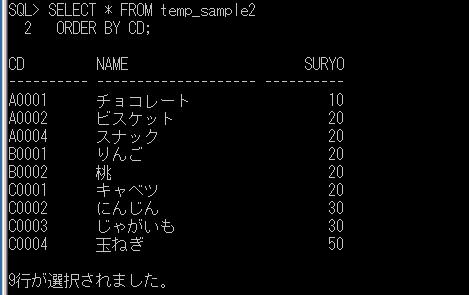
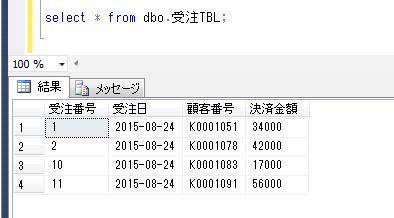
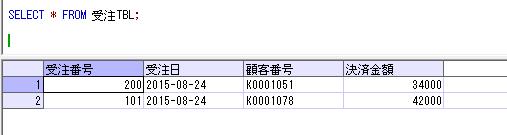
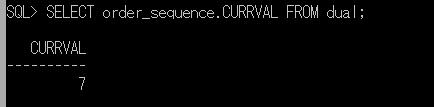
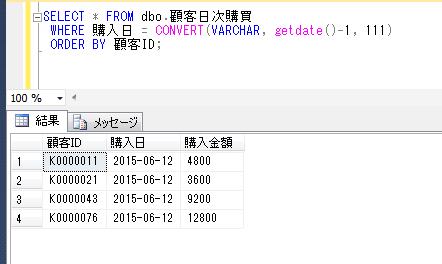
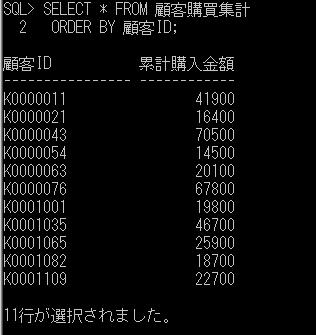
同一のセッションで、このグローバル一時テーブルの中身を確認してみます。
SELECT * FROM ##排他チェック;
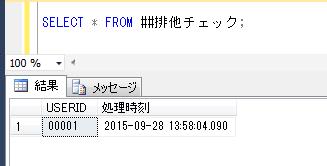
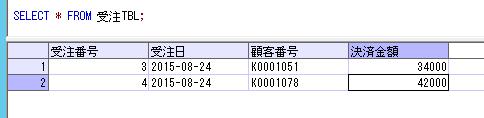
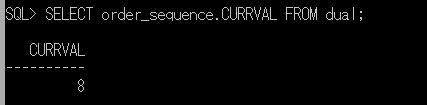
これを、全く別のセッションで異なるUSERIDのメンバーが抽出してみます。
SELECT * FROM ##排他チェック;
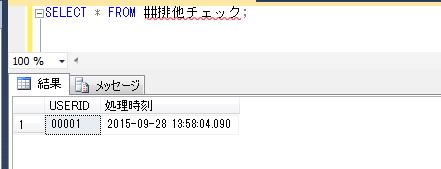
ローカル一時テーブルとは異なり、他のセッションからもデータを確認できます。
ここで、元のグローバル一時テーブルを作成したセッションの接続を解除、もしくは実行していたウィンドウの右上の×の箇所をクリックして閉じてから、再度先ほど確認できた別のセッションからデータを確認してみます。
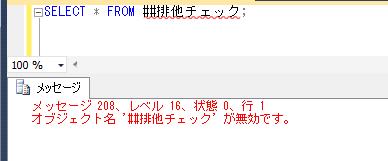
グローバル一時テーブルが接続の解除とともに自動的に削除されたために、データの抽出ができないことが確認できます。
非常に簡単なテストではありますが、このグローバル一時テーブルの存在チェックを行って、存在していれば排他中のため更新不可であり、存在しなければ排他中ではないため、処理を実行してよいという制御をある程度行うことができそうです。
例えば
IF OBJECT_ID(N'tempdb..##排他チェック', N'U') IS NOT NULL
print '他のユーザが使用中のため、実行できません'
ELSE
print '処理を実行します'
上記の処理を、先ほどと同様のタイミングで実行すると、最初に他のセッションでグローバル一時テーブルを作成したタイミングでは、
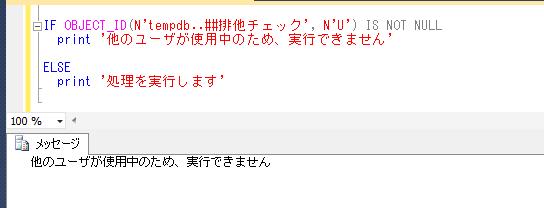
グローバル一時テーブルを作成したセッションの接続を解除した状態では
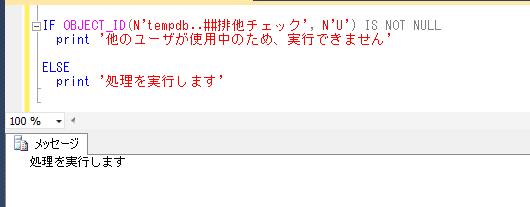
実際には、後から接続して処理を実行する側でも、処理の開始時点で同様に排他用のグローバル一時テーブルを作成するという処理を行うかたちになると思います。
今回は、SQL Serverについて、ローカル一時テーブルだけでなく、グローバル一時テーブルについても試してみました。
今日は以上まで
にほんブログ村